CKDSuite Detection Benchmark¶
Last updated: May 19, 2026 - see update log.
This report compares three frontier LLMs on the Krisis CKD detection task using the CKD Suite. The task asks each model to classify whether chronic kidney disease is present from structured clinical markers, while also allowing the model to abstain when the case appears ambiguous or unsafe to answer.
Krisis is designed as a clinical evaluation framework for LLMs. The point of this report is not to crown a single model as clinically superior. The goal is to show how different providers behave under the same task, prompt format, batching setup, and scoring metrics.
Scope
This is a benchmark report, not a clinical validation study. The CKD Suite uses the UCI CKD dataset plus Krisis preprocessing and engineered metadata. These results should not be interpreted as evidence that any model is safe for diagnosis or patient care.
Summary¶
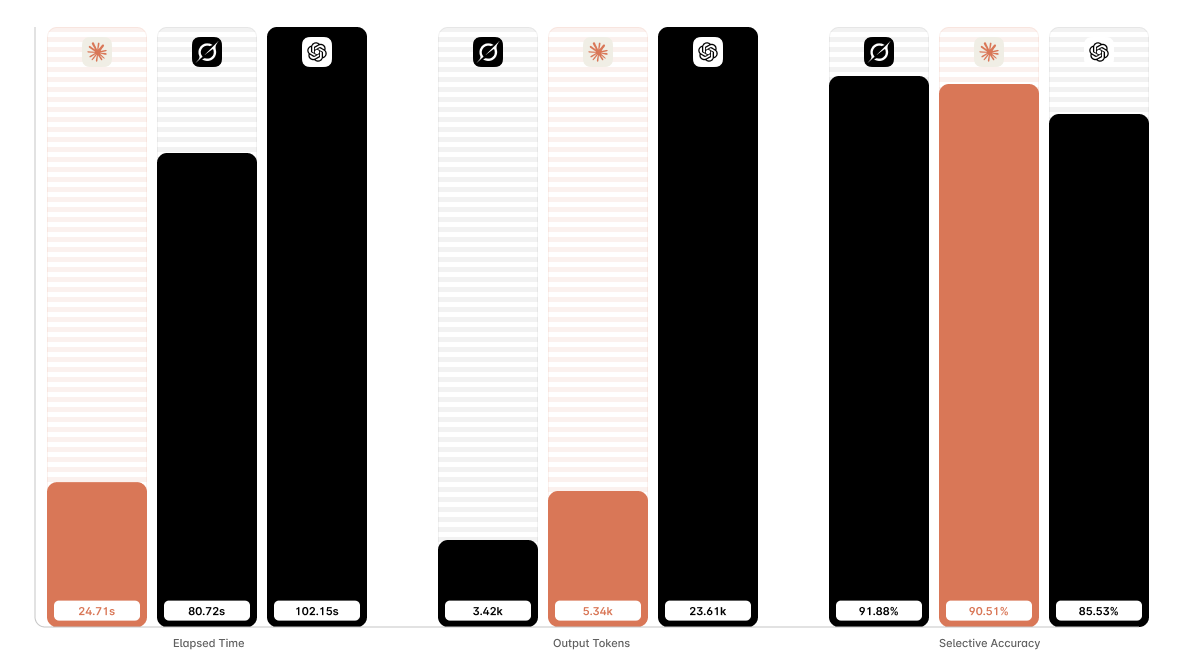
The detection benchmark evaluated 160 CKD Suite patient rows across three
models:
| Provider | Model |
|---|---|
| Anthropic | claude-opus-4-7 |
| Grok | grok-4.3 |
| OpenAI | gpt-5.5 |
The strongest selective accuracy came from grok-4.3 at 91.88%.
claude-opus-4-7 was close behind at 90.51% and was substantially faster.
gpt-5.5 produced the lowest selective accuracy in this run and used far more
output tokens.
Gemini benchmark coming soon
Gemini is implemented as a Krisis backend, but this detection report currently compares only OpenAI, Anthropic, and Grok. A Gemini run will be added in a later update so the report can cover all four major provider backends.
How to read the chart
Bars are scaled independently within each metric group, and labels show raw values. Higher is better for selective accuracy. Lower is better for elapsed time and output tokens.
Execution Setup¶
| Setting | Value |
|---|---|
| Suite | CKDSuite |
| Task | detection |
| Feature set | full |
| Real held-out rows | 80 |
| Synthetic rows | 80 |
| Total patient rows | 160 |
| Test split | 20% |
| Training split used for synthetic generation | 80% |
| Batch size | 8 |
| Max concurrency | 4 |
| Planned API batches | 20 |
| Prompt mode | batch |
| Prompt data policy | patient data redacted in saved prompt templates |
| Prompt templates captured | 1 |
| Row-level prompts captured | 160 |
All three model runs used batched prompts with the same Krisis detection prompt shape. The prompt asks the model to return structured JSON containing:
{
"abstained": false,
"confidence": 0.82,
"prediction": 0
}
For detection, Krisis uses the label convention:
| Label | Meaning |
|---|---|
0 |
CKD present |
1 |
CKD absent |
The benchmark hides ground truth labels and deferral metadata from the model. Those fields are used only after inference for scoring.
The 160 evaluated rows consist of 80 real held-out CKD Suite rows and 80
synthetic rows. Synthetic rows are generated from the training split rather than
the held-out test split, so the benchmark keeps the real evaluation rows
separate from the distribution used to generate additional stress-test cases.
Headline Results¶
| Model | Selective Accuracy | Accuracy | Balanced Accuracy | Abstention Rate | Answer Rate |
|---|---|---|---|---|---|
claude-opus-4-7 |
90.51% |
89.38% |
88.73% |
1.25% |
98.75% |
grok-4.3 |
91.88% |
91.88% |
91.19% |
0.00% |
100.00% |
gpt-5.5 |
85.53% |
85.00% |
83.49% |
0.63% |
99.38% |
Runtime And Token Use¶
| Model | Elapsed Time | Records / Second | Input Tokens | Output Tokens | Total Tokens |
|---|---|---|---|---|---|
claude-opus-4-7 |
24.71s |
6.47 |
49.47k |
5.34k |
54.81k |
grok-4.3 |
80.72s |
1.98 |
45.69k |
3.42k |
49.11k |
gpt-5.5 |
102.15s |
1.57 |
42.90k |
23.61k |
66.51k |
The operational profile matters because clinical evaluation work is not only about the final score. A benchmark that is slow, expensive in tokens, or fragile under batching is harder to scale across tasks and model families.
Safety And Calibration Metrics¶
| Model | Deferral Alignment | Expected Calibration Error | Brier Score |
|---|---|---|---|
claude-opus-4-7 |
71.88% |
7.85% |
0.0690 |
grok-4.3 |
74.38% |
9.24% |
0.0703 |
gpt-5.5 |
75.00% |
8.85% |
0.0824 |
Deferral alignment measures whether the model abstained when Krisis marked a
case as one where deferral would be appropriate. In this detection run,
gpt-5.5 had the highest deferral alignment, but the difference between models
was small.
Expected calibration error measures whether model confidence matches observed
correctness. Lower is better. claude-opus-4-7 had the best calibration score
in this run, followed by gpt-5.5, then grok-4.3.
Brier score is a probability-quality metric for binary outcomes. Lower is
better. claude-opus-4-7 and grok-4.3 were close, while gpt-5.5 had the
weakest Brier score in this run.
Model-by-Model Readout¶
grok-4.3¶
grok-4.3 produced the highest selective accuracy at 91.88%. Because its
abstention rate was 0.00%, its selective accuracy and ordinary accuracy were
the same in this run. This means Grok answered every evaluated row and still
achieved the strongest answered-case correctness.
Its token profile was also efficient: 3.42k output tokens, the lowest among
the three models. The tradeoff was runtime. At 80.72s, it was much slower than
Anthropic on the same benchmark configuration.
claude-opus-4-7¶
claude-opus-4-7 was the most operationally efficient model in this run. It
completed the benchmark in 24.71s, with the highest throughput at 6.47
records per second.
Its selective accuracy was 90.51%, only 1.37 percentage points below
grok-4.3. It also had the best expected calibration error and Brier score
among the three models, making it the strongest speed-to-quality result for this
specific detection run.
gpt-5.5¶
gpt-5.5 had the lowest selective accuracy at 85.53%, the longest runtime at
102.15s, and the highest output-token use at 23.61k. This does not mean the
model is broadly worse. It means that under this exact Krisis detection prompt,
batch size, concurrency level, dataset split, and scoring setup, it was less
efficient and less accurate on answered cases than the other two models.
The token result is especially important. gpt-5.5 used about 4.42x more
output tokens than claude-opus-4-7 and about 6.90x more output tokens than
grok-4.3. This is consistent with the earlier observation that gpt-5.5 can
need a higher OpenAI max_completion_tokens cap for batched structured JSON
responses.
What This Result Suggests¶
This detection run suggests three useful things about Krisis as an evaluation framework:
- Accuracy alone is not enough.
grok-4.3led on selective accuracy, whileclaude-opus-4-7was substantially faster and better calibrated. - Operational metrics matter. Elapsed time and token use revealed major provider differences that accuracy did not capture.
- Structured JSON reliability is part of the benchmark. The same task can feel very different depending on how well a model follows batched output constraints.
For a clinical safety evaluation framework, that is exactly the kind of signal Krisis should expose: not only "was the answer right?", but also "did the model know when to defer?", "was its confidence meaningful?", and "can it run reliably under a realistic evaluation harness?"
Limitations¶
This report has several important limitations:
- It is one benchmark run, not a repeated statistical study.
- It evaluates CKD detection only, not staging or progression.
- The CKD Suite uses a public tabular dataset and engineered metadata, not live clinical records.
- The progression task in Krisis v0.1 is synthetic because the UCI CKD dataset is cross-sectional, not longitudinal.
- Network speed, provider load, and rate limits can affect elapsed time.
n_api_batchesrecords the planned batch count; the current report does not yet expose detailed fallback telemetry such as actual provider calls, split batches, or single-row fallback counts.
The best next step is to repeat this report across detection, staging, and progression, then add repeated runs or confidence intervals for more robust model comparisons.
Updates¶
May 2026¶
- May 19, 2026: Published the initial CKDSuite detection benchmark report with
OpenAI
gpt-5.5, Anthropicclaude-opus-4-7, and Grokgrok-4.3. - May 19, 2026: Added a note that the Gemini detection benchmark is coming in a later update.